1. はじめに
2年ほど前から、同じテーマで発表させてもらっている。振り返ってみて、これまでの発表では、われわれがどこにこだわっているのか、そもそもの着眼点をうまく伝えられてこなかったと思われる。そこで、今回は、われわれの着眼点に重点を置いて発表する。
われわれのテーマと取り組み
われわれは、通常の意味の文書に対して、新たな《読み》《書き》の可能性をひらきたいと考えている[1]。これらの文書の記述的で定性的な特徴に着目し、人々が意識的・無意識的に行っていると思われる《読み》方、《書き》方を見つけて、それを《読み》《書き》ツールとして実装しながら明らかにしていく[2] [3]というアプローチをとっている。
われわれのアプローチにおいては、XHTMLを各ツールに共通な文書データフォーマットとして採用し、ツール実装にはxfy[8]を採用している。XHTMLを文書データフォーマットに採用することで、その読み方で読める文書が、ネットに多数存在することになる。また、その書き方で書いた文書を、広く一般的に読むことができる。また、実装にxfyを採用することで、各ツールはツール固有の読み・書き機能のみを実装すれば、既存の読書・編集環境と補い合う形で、全体としての読書・編集環境を発展させていくことができる。ここに、われわれのアプローチの優位性がある。
われわれのスコープは、いわゆる通常の意味での文書であり、帳票や定量情報にはあまり重きをおいていない。また、これらを単に読んで参照するだけではなく、書いて編集することも重要である。
この取り組みは発想支援にも関係している。文書の《読み》《書き》に試行錯誤や発散的・収束的思考を導入することで、新たな《読み》《書き》の可能性がひらかれるのではないか[4] [5]。
この取り組みは知識共有にも関係している。《読み》方や《書き》方の一部を、人々の頭の中からICT環境に《外在化》し電子的な手段として実装すると、知識共有を促進するのではないか[5] [6]。
この報告の構成
この報告では、XMLの観点から、われわれの取り組みの着眼点について詳しく論じて、課題とアプローチを簡単に紹介し、実装例にて再び着眼点を具体例で論じる。
われわれは、文書を、要素の入れ子(木構造)として構造化することが、文書の新たな《読み》《書き》の可能性をひらくために有効であると考えている。そこで、われわれが文書データの記述に採用しているXHTMLはXMLであり、《読み》《書き》ツールの実装に採用しているxfy[8]は、XMLベースのメタ文書エディタである。
2. マークアップと通常の意味での文書
われわれの着眼点は次の2つである:
まず、意味与奪型から説明しよう。
2.1 XMLとマークアップ
Text consists of intermingled character data and markup. [Definition: Markup takes the form of start-tags, end-tags, empty-element tags, entity references, character references, comments, CDATA section delimiters, document type declarations, processing instructions, XML declarations, text declarations, and any white space that is at the top level of the document entity (that is, outside the document element and not inside any other markup).]
Extensible Markup Language (XML) 1.1 (Second Edition)[7]
マークアップ利用のアプローチ
このようなマークアップの意味や構造を具体的かつ厳密に設計して、データをマークアップで記述して、正確に、高速で、大量に、かつ自動的にプログラムで処理しようとする取り組みは、従来から行われてきた。また、そのような意味や構造を標準化して、システム間で相互運用を可能とする取り組みも、やはり従来から様々に行われている。XMLは、このようなデータ記述形式として定着している。
このようなアプローチを意味駆動型とわれわれは呼ぶ。
これに対しわれわれは、文書の区切りそのものが、対話的な編集の操作性を高める点に着目している。マークアップが抽象的であっても、あるいはシステムがマークアップの具体的な意味に踏み込んだ機能を持たなくても、そのマークアップを役立てることができると考えている。このような視点での技術開発が、これまで不足していたのではないだろうか。
このようなアプローチを意味与奪型とわれわれは呼ぶ。
両者の取り組みは、相互に補い合うものである。なぜなら、文書のどの部分をマークアップするかということは、そのマークアップにどのような意味を持たせるかということと不可分だからである。無意味で一貫性を欠いたマークアップでは、利用者に効果的な編集機能を提供することはできない。
以降、この報告では、文書の区切りそのものを、《マークアップそのもの》と呼ぶことにする。
マークアップとその意味
マークアップの意味に基づいて処理するのと区別して、マークアップそのものが役立つとはどういうことか。HTMLと対比することでXMLを導入する場合を例に、この着眼点を説明しよう。
XMLを学び始めたとき、HTMLと対比して、図1のようにXMLの特長を理解した覚えはないだろうか?あるいは、HTMLからXHTMLへの移行に際して、文書の構造を記述する意味マークアップの特長を、このように理解したであろう。
- HTMLのB要素などは、個々の要素の表示を指定することで、ブラウザウィンドウの幅などに応じて、文書全体を自動レイアウトできる。XMLでは、個々の要素の意味を指定することで、自動レイアウトだけでなく様々な目的に応じて、文書を機械的に自動処理することが可能である。
- HTMLでは、あらかじめ決められたタグしか用いることはできない。XMLでは、新たなタグを導入して、本来記述したかった意味や構造を表現できる。
| HTMLの場合 | XMLの場合 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
<table> <tbody> <tr> <td>タイトル</td> <td>日時</td> <td>場所</td> </tr> <tr> <td>第66回DD研</td> <td>2008年6月6日</td> <td>大森ベルポート</td> </tr> </tbody> </table> |
ソース |
<event> <summary>第66回DD研</summary> <dateTime>2008-06-06</dateTime> <location>大森ベルポート</location> </event> |
||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
できない、あるいは貧弱。 「2008年6月6日」が日時であることは、これを見た人間には分かるが、この情報を処理するプログラムには分からない。 |
内容の意味に基づいた自動機械処理 |
できる。 「2008-06-06」が日時であることは、dateTimeという名前のタグによって示され、プログラムはこれを日時として処理することができる。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
ブラウザでそのまま表示できる。 例えば:
|
人間用に表示 |
様々に変換・加工して表示できる。 例えば:
|
図1 HTMLと対比してXMLのメリットを理解する例
このような理解そのものは正しい。しかし、このように理解したときに、併せて次のように思い込んでいないだろうか。
- その内容の意味を表現するタグをつけて、その意味に基づいて自動機械処理するのでなければ、文章をマークアップすることにさしたる効果はない。
われわれの着眼点は、しばしばこのようにして見過ごされがちである。すなわち、われわれは、そのようなマークアップでも効果があると考えている。その意味に特化した機能がシステムに実装されていなくても、利用者が意味を了解できるのであれば、そのマークアップに基づく効果的な機能を提供するシステムがありうると考えているのである。
マークアップを利用する機能
マークアップに基づく効果的な機能の例をあげよう。ここでは、身近な例をあげるために、XMLにこだわらず、従来からあるエディタ、ワープロやアイデアプロセッサーで実現されている機能を見る。
これら機能の便利さは、次のような効果からもたらされると考えられる。
ここで留意すべきは、これら効果は、マークアップの意味に基づくというよりも、「そのように区切られている」というマークアップそのものに由来する、ということである。
すなわち、利用者は章をその意味に基づいて移動するが、その操作を支援するワープロがその章の意味を知っているわけではない。
図1の表を図2のように、含まれるイベントを増やして少し複雑にしてみよう。
| タイトル | 第66回DD研 |
第67回DD研 |
第68回DD研 |
| 日時 | 2008年6月6日 |
2008年7月24日(木)、25日(金) |
9月26日 |
| 場所 | 大森ベルポート |
北海道大学 |
大森ベルポート |
↓ 日時を選択
| タイトル | 第66回DD研 |
第67回DD研 |
第68回DD研 |
| 日時 | 2008年6月6日 |
2008年7月24日(木)、25日(金) |
9月26日 |
| 場所 | 大森ベルポート |
北海道大学 |
大森ベルポート |
↓ 日時を一括削除
| タイトル | 第66回DD研 |
第67回DD研 |
第68回DD研 |
| 場所 | 大森ベルポート |
北海道大学 |
大森ベルポート |
図2 複数のイベントを含む表
図2で、表編集機能を実装したエディタであれば、2番目の行を選択して、複数のイベント情報から日時部分を一括して削除することができる。このとき、2行目が日時であることを知っているのは利用者であって、エディタではない。それにもかかわらず、簡単な操作で日時を削除することができる。
大域的編集
ここで、前節で述べた大域的編集を定義しておこう。
文書中の互いに関係する部分は、必ずしも連続して配置されていない。これは、文書がレイアウトされたページ上だけでなく、ソースデータ構造上も、である。このために、大域的編集が必要となる。
マークアップそのもの
マークアップそのものと呼んでいるものは、その意味と独立ではない。例えば図1のHTMLの表を図3のように、table、trなど全てのタグ、すなわちマークアップの名前を、同じacbに書き換えたらどうか?これでは、これを表として、行・列・セルの編集機能を利用者に提供するには、多少込み入った処理とUIを伴うことになるだろう。
<acb> <acb> <acb> <acb>タイトル</acb> <acb>第66回DD研</acb> </acb> <acb> <acb>日時</acb> <acb>2008年6月6日</acb> </acb> <acb> <acb>場所</acb> <acb>大森ベルポート</acb> </acb> </acb> </acb>
図3 意味を大幅に捨象したマークアップ
すなわち、われわれがこの報告で《マークアップそのもの》と呼ぶのは、次のようなものである:
- 編集操作の観点から規定されるデータ構造である。
- その編集操作を提供するプログラムは、利用者が了解しているよりも、かなり抽象的な意味に基づいて処理する。
- 要素の区切りは明確である。
- その処理は、表組みや箇条書きなど、伝統的なページや文書の組み方を利用することで、利用者にとって分かり易いものとなる。
ここで、かなり抽象的な意味と言っているのは、例えば、次のようなものである:
- 情報には種類があって、それらは互いに区別される。
- ある情報が、複数の要素情報の集合として表現されている。
- それら要素集合の順序に、意味があったりなかったりする。
- 要素情報の種類は同じだったり、異なったりする。
- それら要素情報は、さらに複数の要素情報の集合として表現されている。
入れ子(木構造)マークアップの特徴
マークアップそのものと呼んでいるものは、その意味と独立ではないが、別の概念である。最後にそれを示そう。
XMLのマークアップは、入れ子構造になっているため、要素の部分的なオーバーラップを表現できない。図4では、虹の七色について、小林が暖かい色の範囲を、山口が冷たい色の範囲をマークアップしている。緑色が両方に含まれているが、XMLではこのようなオーバーラップは許されない。
<暖 by="小林">赤、橙、黄、<冷 by="山口">緑</暖>、青</冷>、藍、紫
暖要素と冷要素がオーバーラップしている。「緑」が両方に含まれているが、「赤」は暖要素のみ、「藍」は冷要素のみに含まれている。
図4 部分的にオーバーラップする要素
すなわち、どのように区切るかということと、その区切りにどんな名前を付けるのか、どんな意味があるのかとは、別の概念である。
どのような区切りを許すかは、われわれが着目するような処理系の機能やわかりやすさに影響する。例えば、表でセルの結合が可能なエディターの場合、そのような表で行・列の削除や移動したときの振る舞いに、違和感を覚えたことのある利用者は多いだろう。
2.2 通常の意味での文書
続いて、通常の意味での文書を説明する。
XMLでは、電子商取引の請求書も文書(XML document)である[7] 。
[Definition: A data object is an XML document if it is well-formed, as defined in this specification. In addition, the XML document isvalid if it meets certain further constraints.]
Extensible Markup Language (XML) 1.1 (Second Edition)[7]
小説や報告書などを「通常の意味での文書」と呼んで識別するとき、われわれは次の特徴に着目している。
われわれは、このような通常の意味の文書を記述的文書、定性情報、あるいは自然文と呼ぶことがある。
記述的文書
記述的(narrative)とは、規範的(prescriptive)と対になる概念である。事前に正しい用法が定義されたマークアップがあり、それを使って記述できることを前提とした文書が規範的文書である。帳票などがこれに該当する。これに対し、そのようなマークアップの事前定義を前提としないものを、記述的文書と呼ぶ。
正確には、記述的部分と規範的部分は1つの文書で混在する。記述的文書という文書の種類があるというより、文書には記述的な部分、記述的な作成・利用局面や記述的な内容レベルがあると考えるのが適切であろう。
帳票でも、例えば、購買の「申請理由」欄の内容は記述的であろう。申請が、「金額」によって機械的に認可されることもあれば、「申請理由」によって判断されることもある。「申請理由」による判断は、そのときどきの経営状態などによって行われ、審査するものが読み取る内容は規範的とは言い難い。このため、申請者は「申請理由」を記述するときに試行錯誤することになる。
推理小説にも規範的な情報が含まれる。本の流通局面を考えれば、「書名」、「著者」や「ISBN」などの書誌情報は、正確な使用が求められるし、それによって、大量の在庫から瞬時に本を探し出すことができ、注文した本が正しく届く。
また、小説においても「段落」や「見出し」といったマークアップは規範性が高い。しかし、「真犯人」や「正義」というマークアップの付いた推理小説は希であろう。それでも、作者や読者は「真犯人」や「正義」を巡って情報処理しているはずである。
定性情報
定性情報とは、定量・コード化情報と対になる概念である。一般的には、定量情報とは、対象の量的な側面に着目し、尺度を設定して、その数値を用いて対象を記述し分析するものである。ここでは、数値でなくても、あらかじめ用意された分類にあてはめるコード化と併せて、定量・コード化された情報と対になる概念として、定性情報を考える。すなわち、われわれが着目する点は、記述的・規範的と同様である。
2.3 まとめ
われわれの2つの着眼点は、次のように関係している:
すなわち、通常の意味での文書には、意味与奪型のアプローチが向いている。
3. 課題
以上の着眼点から、われわれの課題は、記述的文書に対する意味与奪型の文書編集・読解機能を発見することである。
これによって、利用者には次のようなメリットがあるだろう:
- 小さな・簡単な操作で大域的・複雑な編集・読解ができる。
- 容易に試行錯誤できる。
このような文書編集機能が効果を発揮するのは、試行錯誤の場面であろう。文書の内容を試行錯誤しながら書いている段階では、各要素の意味は不確定である。本質的に、十分な意味づけができない要素を編集する場面でこそ、われわれの着眼点が生きるはずだ。
4. アプローチ
上記の課題を達成するため、われわれは次のアプローチをとることとした:
- 試行錯誤の場面を観察して、そこで行われる操作を実装してみる。
- 特定の要素、属性、属性値への依存性を減らす。
- XHTMLで文書を記述することとし、極力、新たな要素、属性、属性値を発明しない。
- 表組みや箇条書きなど、伝統的なページや文書の組み方を利用する。
これによって、利用者にとって直感的で分かり易いプログラムとなるだろう。
5. 実装例
そのようにして開発した文書編集プログラムの例を紹介する。
STORYWRITER
STORYWRITER[2] [9]は、多色マーカーツールである。文書の読者は、自由にマーカーを追加することができる。また、マークを手掛かりにして文書の部分を 並べ替えることができ、文書を読み解く助けにすることができる。さらに、マークを手掛かりにして、文書を編集することができる。
機能
読者がマーカーを追加すると、それに応じて、STORYWRITERは、class属性の値を新規に用意する。読者が文書の部分をマークすると、STORYWRITERは、その部分をem要素で囲い、そのマーカーに対応するclass属性値を設定する。
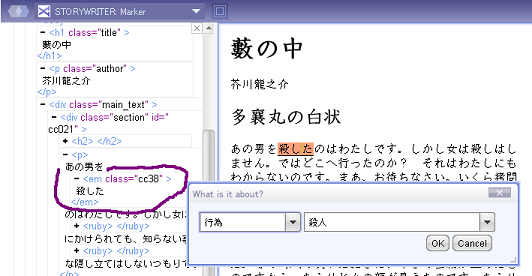
図5 マーカーはクラス属性で区別される
図5では、読者が"殺人"とマークした部分に、"cc88"というclass属性値が設定されている。em要素とは、HTMLで強調を表す要素である。
STORYWRITERのCrossビューでは、同じclassのem要素が、表の同じ行に抜き書きされる。

図6 STORYWRITERのクロスビュー
図6では、class属性値が"cc011"であるem要素を抜き出して、表の同じ行に配置している。ここで、class属性値が"cc011"であるem要素は、UI上は"視線"というマーカーに対応している。
すなわち、こことここは同じ意味だということだけを前提に、役に立つ文書操作機能を提供できた。それぞれの括りの意味は、ユーザーだけが知っている。それでも、利用者に便宜を提供することができている。
開発経緯
STORYWRITERの開発当初は、"When"や"Where"といった特別な値がclass属性値として設定されていた。すなわち、時間や場所は普遍的で客観的だからビルトインマーカーとして用意して良いだろうと考えていた。
しかし、素材とした「藪の中」では、"午少し過ぎ"や"その内にやっと気がついて見ると"など、幅のある時刻や主観的な時間経過の記述がある。また、この物語そのものが、登場人物の供述の食い違いをポイントとする平行物語であり、それぞれの主観的な主張にこそ物語の本質があり、《読み》の面白さがある。客観的な時間を特別扱いしたところで、この《読み》に対して、さして寄与するところはないのではないか。スケジューラーのような便利さを実現できないであろう。むしろ、システムが複雑になるデメリットが大きいと考えた。
SayYes!
6. 考察
段落(Paragraph)という意味
CSVの快適さ
関心の分離
所望のレイアウトを得る試行錯誤
WYSIWYGの長所は、所望のレイアウトを得るための試行錯誤を容易にしたことにある。
《マークアップ》そのものを手掛かりにする機能が容易にする試行錯誤は、所望の印刷レイアウトを得るための試行錯誤だけでなく、所望の文書の内容を得るための試行錯誤である。
所望のレイアウトは、書き手が意図する文書の構成と密接に関連していると考えられる。したがって、これらを得るための試行錯誤も密接に関連しており、WYSIWYG機能の発展は、間接的に、文書内容編集の試行錯誤機能の発展でもあった。
マークアップと指示語
われわれがやろうとしていることは、指示語の働きを、電子的・定性的な情報交換、情報利用に持ち込み、その品質を高めて効率を向上し、記録に残すものなのかもしれない。
7. まとめ
この報告では、マークアップそのものに着目するという、われわれの取り組みの特徴を論じ、実装例を示した。
実装例を見て、「なるほど。そういうことなら、こういうのもアリではないか?」と思ってもらえれば幸いである。われわれは、もっと多くの、このような実装がありうると考えている。
文献
- [1] 山口琢: Web文書のusabilityを高める"Slide Show for XHTML"、情報処理学会研究報告Vol.2006, No.83(20060728) pp. 55-58 (2006.7)
- [2] 小林龍生、山口琢: Parallel Narratology試論 : ハイパーテキストにおける相互参照の観点から、情報処理学会研究報告Vol.2007, No.77(20070726) pp. 25-30 (2007.7)
- [3] 山口琢、新ワードプロセッシング : CrossConcept、Template It!の試作、情報処理学会研究報告Vol.2007, No.77(20070726) pp. 31-35 (2007.7)
- [4] Taku Yamaguchi, Tatsuo Kobayashi: Implementing CrossConcept: A Computer Software Supporting Creative Thinking、IJCKS 2007 (KSS2007/KICSS2007) (2007.11)
- [5] 山口琢、小林龍生、野口尚孝: CrossConceptにおける概念操作モデルと知性・感性の工学的支援、第2回横幹連合コンファレンス (2007.11)
- [6] 大場 みち子、山口琢: プロセスとしてのドキュメンテーション、情報処理学会研究報告Vol.2008, No.10 (2008/1・2/31・1) pp. 131〜137 (2008.1)
- [7] World Wide Web Consortium: Extensible Markup Language (XML) 1.1 (Second Edition) (2006.9)
- [8] 株式会社ジャストシステム: xfy Community
- [9] 山口琢: STORYWRITER、http://www.yamahige.jp/storywriter/
- [10] Wikipedia contributors, 'マークアップ言語', Wikipedia, , 24 5月 2008, 04:06 UTC, <http://ja.wikipedia.org/w/index.php?title=%E3%83%9E%E3%83%BC%E3%82%AF%E3%82%A2%E3%83%83%E3%83%97%E8%A8%80%E8%AA%9E&oldid=19834878> [accessed 28 5月 2008]